 Für ein zentrales Data Warehouse, welches umfangreiche Datenmodellierungsprozesse mit vielen Quellsystemen, großen Datenmengen oder sich stetig weiterentwickelnde Geschäftslogik hat, bietet das Data Vault-Konzept eine zuverlässige und flexible Lösung an.
Für ein zentrales Data Warehouse, welches umfangreiche Datenmodellierungsprozesse mit vielen Quellsystemen, großen Datenmengen oder sich stetig weiterentwickelnde Geschäftslogik hat, bietet das Data Vault-Konzept eine zuverlässige und flexible Lösung an. Die Daten werden nicht wie bisher in der 3. Normalform abgelegt, sondern in Kategorien eingeteilt.
- Hub: Enthält pro Entität (z.B. Kunde) den Businesskey.
- Link: Bildet die Beziehung zwischen Geschäftsobjekten ab.
- Satellite: Enthält die beschreibenden Attribute von Hubs und Links.
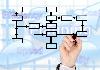
Zur veranschaulichen der Unterschiede zwischen den beiden Ansätzen wird im Folgenden ein vereinfachtes Modell betrachtet:
Ein Bestellung besteht aus einem Kunden und einem Produkt.
In Data Vault gibt es zu jedem Kunden genau einen HUB-Datensatz. Das Feld "HUB_KU_SID" enthält die SID, die aus dem Business Key mit MD5 berechnet wird.

Zu jedem Kunden kann es in Data Vault mehrere SAT-Datensätze geben. Bei jeder Änderung wird ein neuer Datensatz erzeugt.

Damit wird ein Datensatz eindeutig durch die SID und dem Ladedatum identifiziert. Dadurch, dass zu jedem Datensatz das Ladedatum mit eingetragen wird, erlaubt die Data Vault Modellierung eine unitemporale Historisierung.
In der nächsten Graphik wird das Modell des Beispiels in den beiden Konzepten dargestellt. Im Data Vault Modell hat man zwar mehr Tabellen, aber es gibt keine Vermischung von Schlüsseln und Attributen. Im 3. NF führt die Tabelle Bestellung sowohl Fremdschlüssel als auch Attribute. Dies kann bei einer Beladung (Beachten von Abhängigkeiten) als auch bei einer Erweiterung inflexibel sein.
Durch die Modellierung in Data Vault kann bei einer Erweiterung z.B. Anbindung eines weiteren Quellsystems für den Kunden, eine weitere SAT-Tabelle hinzugefügt werden. Dies führt lediglich dazu, dass eine zusätzliche ETL-Strecke erstellt wird. Die bestehende SAT-Tabelle wird dabei nicht geändert und damit auch nicht der bisherige Job. Das Datenmodell bleibt damit stabil und kann inkrementell erweitert werden.
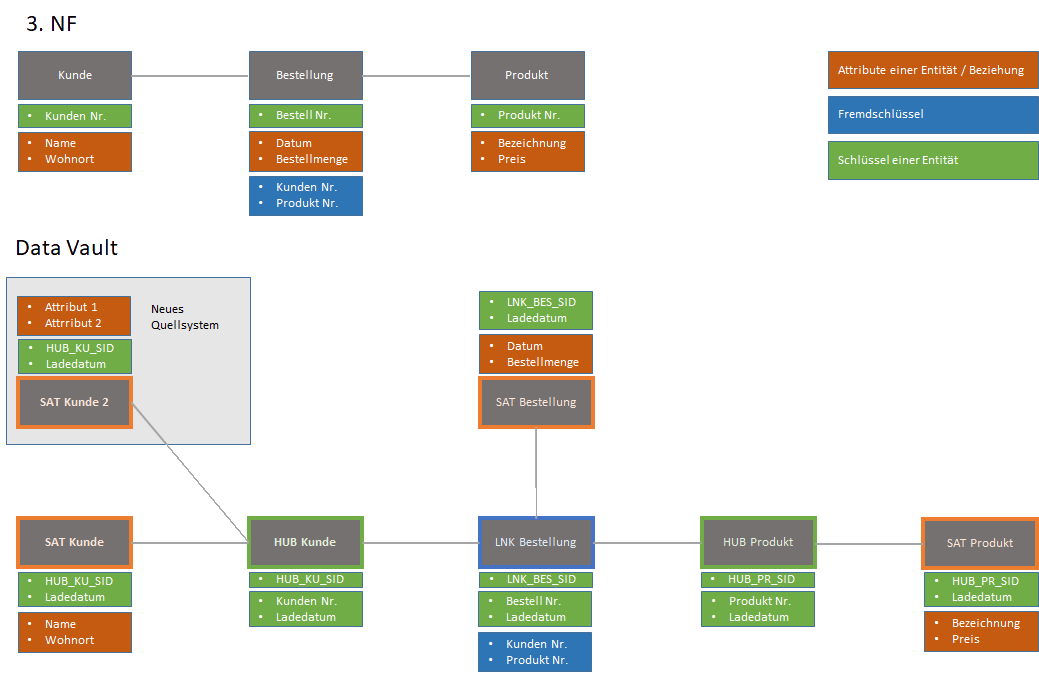
Starke Parallelisierung der Datenladeprozesse
Die Beladung bei Data Vault erfolgt immer auf die gleiche Weise und ist auch einfach zu parallelisieren, da zwischen den Objekten einer Kategorie keine Abhängigkeiten herrscht. Z.B. kann die Beladung der Hubs gleichzeitig erfolgen.
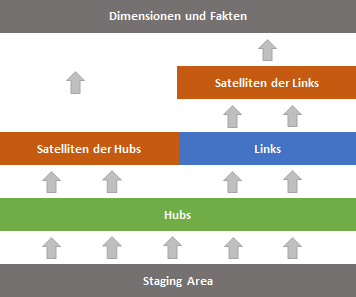
Automatische Generierung von ETL-Strecken (Informatica PowerCenter)
Aufgrund der Einteilung der DataVault Tabellen in Kategorien (HUB, LINK, SATELLITE) und der strukturgleichen Bewirtschaftung der jeweiligen Kategorie kann die Erstellung der Mappings von der Stage bis zum Core automatisiert werden.
Hierzu greift z.B. ein Java-Programm auf die Meta Daten einer Datenbank zu, die im DWH-Datenmodell (z.B. ERwin) hinterlegt sind. Im Datenmodell wird beschrieben, aus welchen Sourcefeldern ein Zielfeld aufgebaut ist. Diese Informationen werden im XML-Format exportiert und dienen dem Java-Programm als Input. Das Java-Programm erstellt aus diesen Informationen und dem Java API for Informatica die entsprechenden Mappings. Als Output werden dann die Mappings im XML-Format zur Verfügung gestellt, die dann in Informatica PowerCenter importiert werden können.
 metaLogix bietet Funktionen für die Auswertung von Business-Intelligence Daten. Auf der Basis der Metadaten von SAP Business Objects werden Erkenntnisse über Ihre gesamten Berichtswesen sowie der Attribute gewonnen.
metaLogix bietet Funktionen für die Auswertung von Business-Intelligence Daten. Auf der Basis der Metadaten von SAP Business Objects werden Erkenntnisse über Ihre gesamten Berichtswesen sowie der Attribute gewonnen.